RLEF-DataGen
Harnessing Expert Feedback to Generate Representative Synthetic Clinical Data for Underserved Populations
June 27, 2025
Our Approach: Reinforcement Learning with Expert Feedback
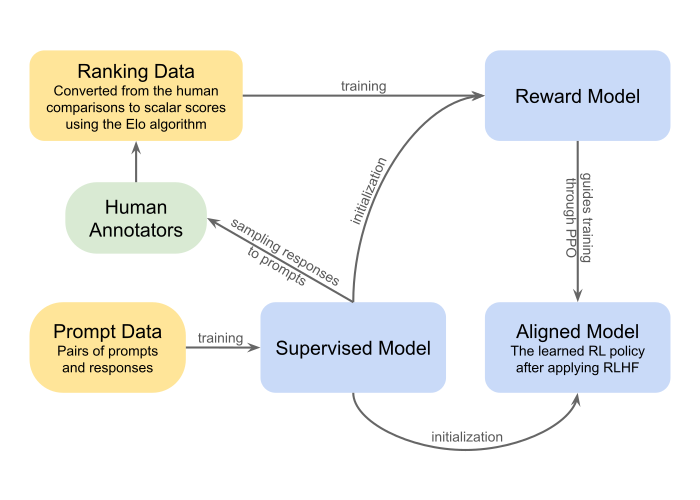
Note:
RLHF and RLEF are not exactly the same thing. RLHF is about learning what humans like; RLEF is about learning to do what experts do. RLHF handles subjective alignment, while RLEF handles competence transfer.
Traditional AI Implementation Framework: CRISP-DM

CRISP-DM Extended

Key Addition: Feedback Loops. Models change the world they operate in
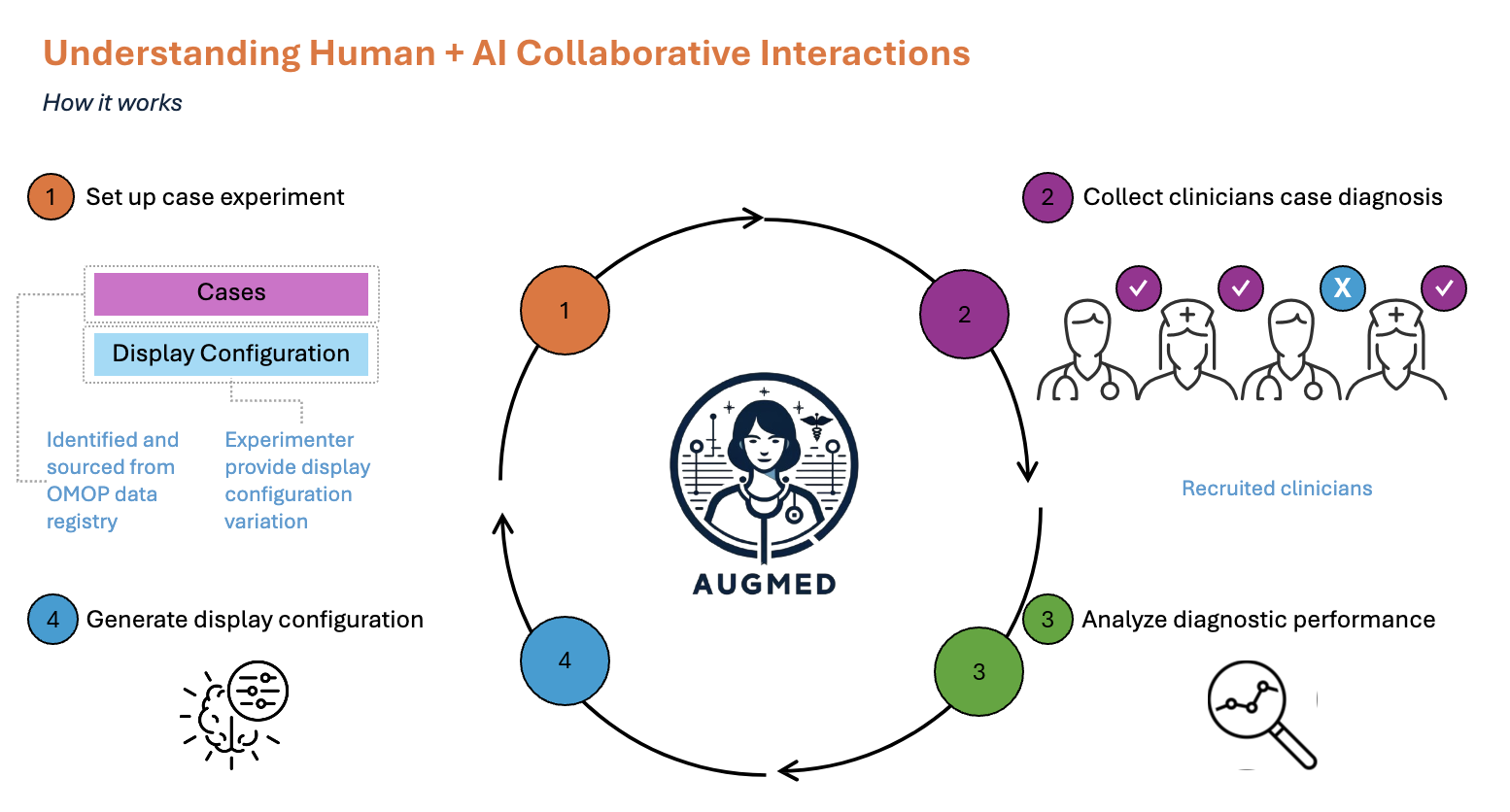
RLEF as a Socio-technical System
AugMed Platform
 }
}
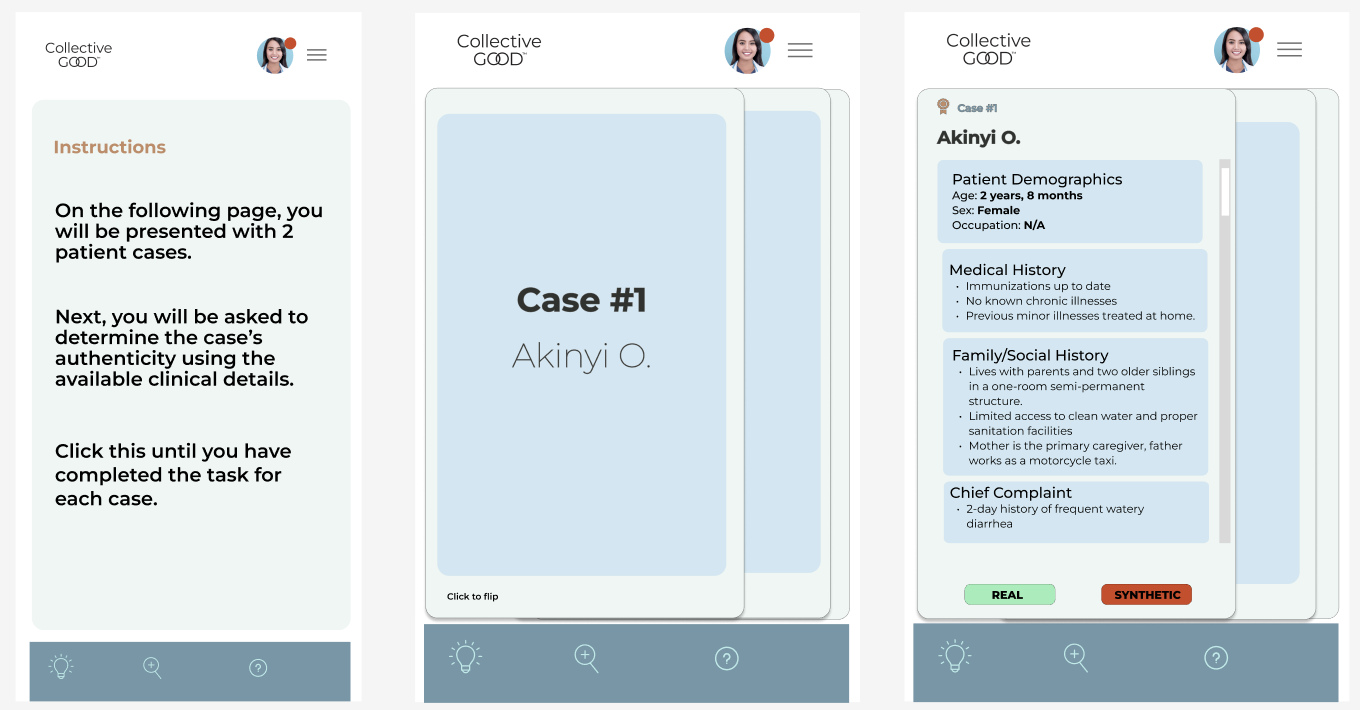
Example Platform UI - Smartphone Version
 }
}
Here: Clear binary choice
References
Key Sources:
- OECD (2023). Progress on implementing and using electronic health record systems.
- Celi et al. (2022). Sources of bias in artificial intelligence that perpetuate healthcare disparities. PLOS Digital Health.
- Fortune Business Insights (2023). Synthetic Data Generation Market Forecast 2030.
- ONC/HealthIT.gov (2021). National Trends in Hospital and Physician Adoption of Electronic Health Records.
- Gartner (2023). Predicts 2024: AI and Machine Learning.
- NIH N3C (2020). National COVID Cohort Collaborative synthetic data initiative.
- Sylvia, S. (2025). Digital Health and the Leapfrog Illusion: Socio-technical Systems in Global Health.